Benchmarks
Measured on real laptops.
Every FastFlowLM release is validated on Strix Point and Halo reference designs.
We publish the results in docs/benchmarks so teams can compare apples-to-apples.
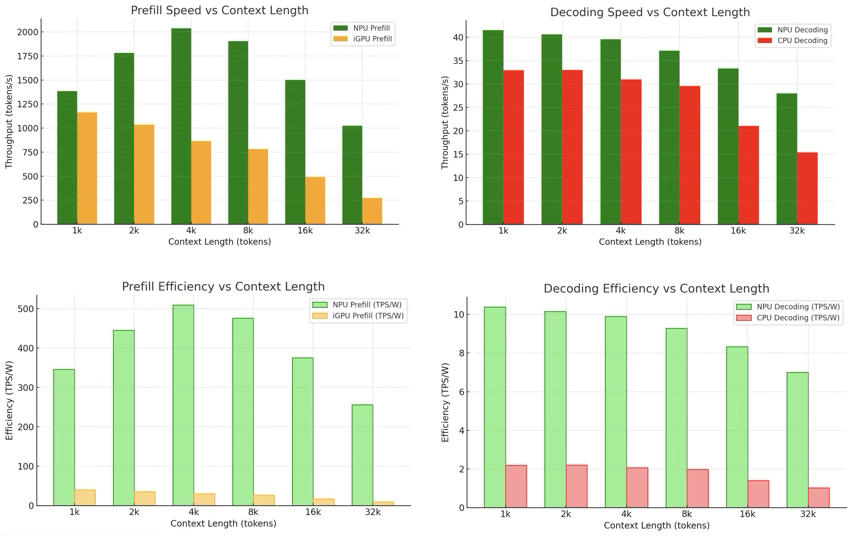
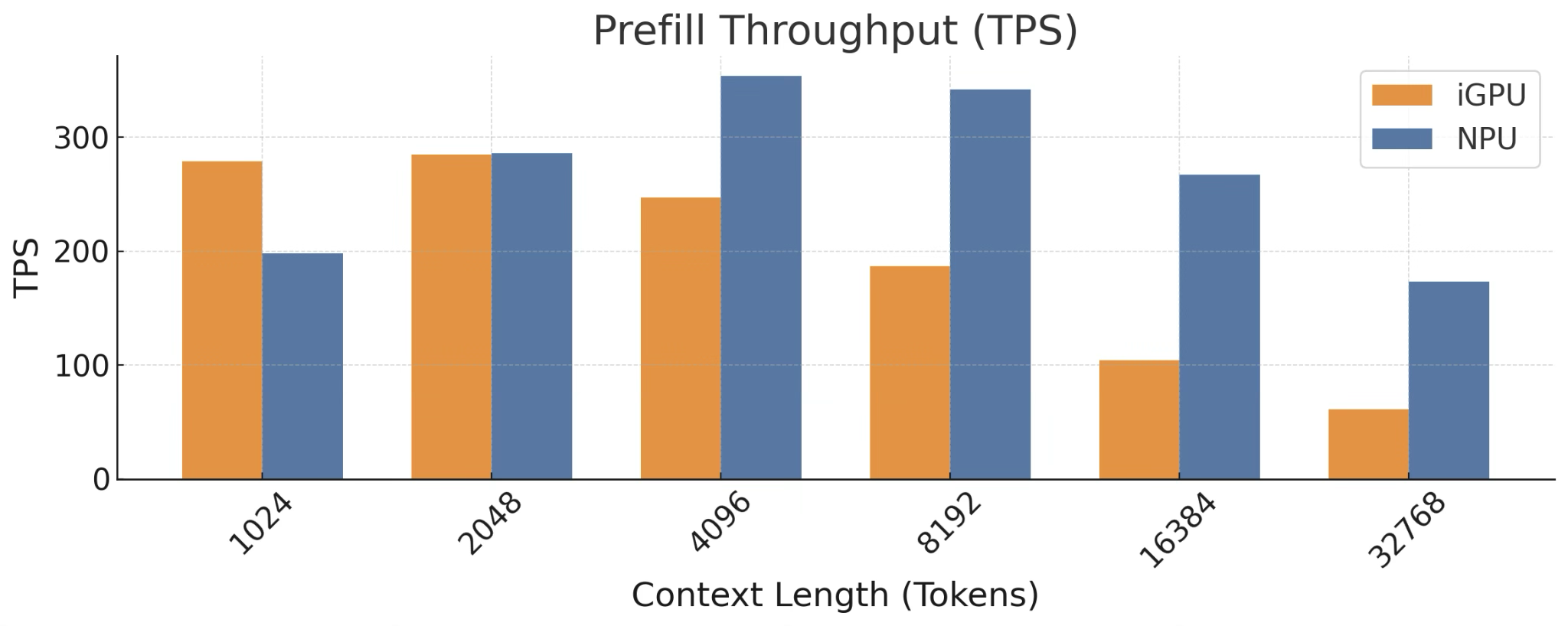
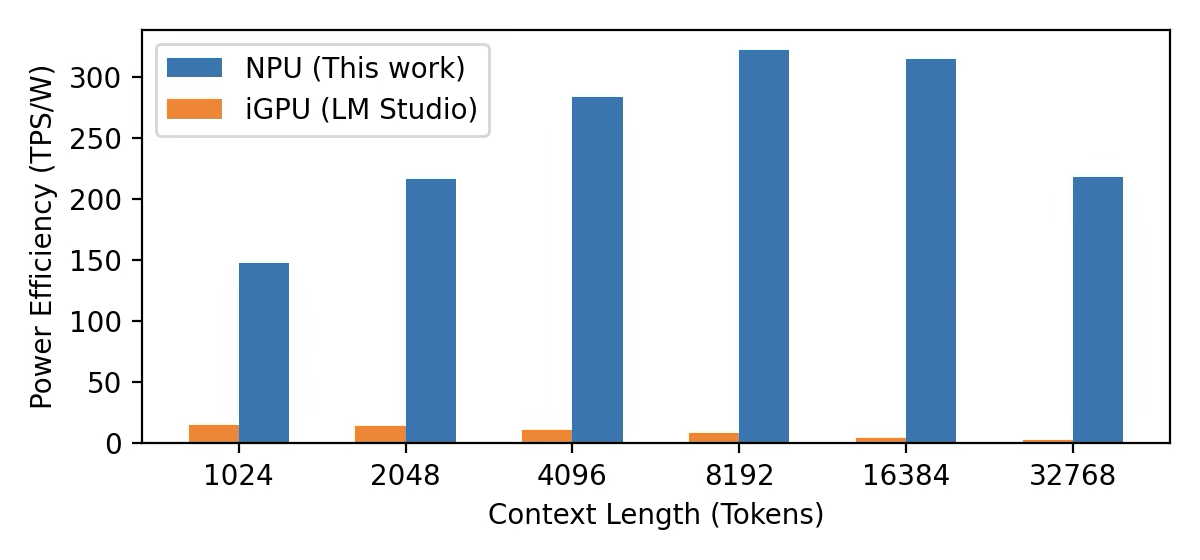
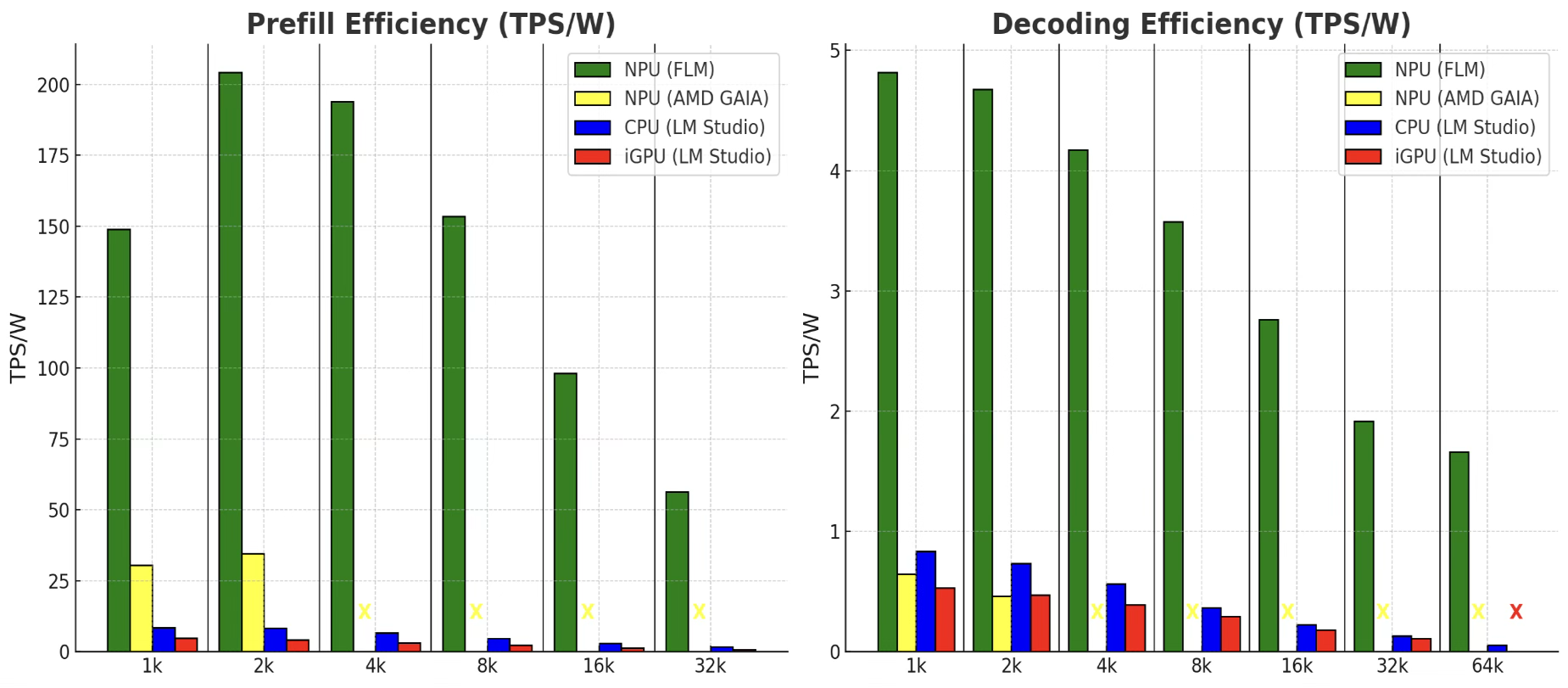
The runtime extends AMD’s native 2K context limit to 256K tokens for long-context LLMs and VLMs and, in power efficiency tests, consumes 67.2× less power than the integrated GPU and 222.9× less power than the CPU on the same chip while holding higher throughput.
Llama3.2 1B
62.7 tps
AMD Ryzen™ AI 7 350 with 32 GB DRAM
Qwen 3 0.6B
53.7 tps
Prefill speed: 1,280 tps
Gemma3 1B
40 tps
Prefill speed: 1,004 tps
Llama 3.2 on Ryzen™ AI
Prefill + decoding throughput across 256K tokens
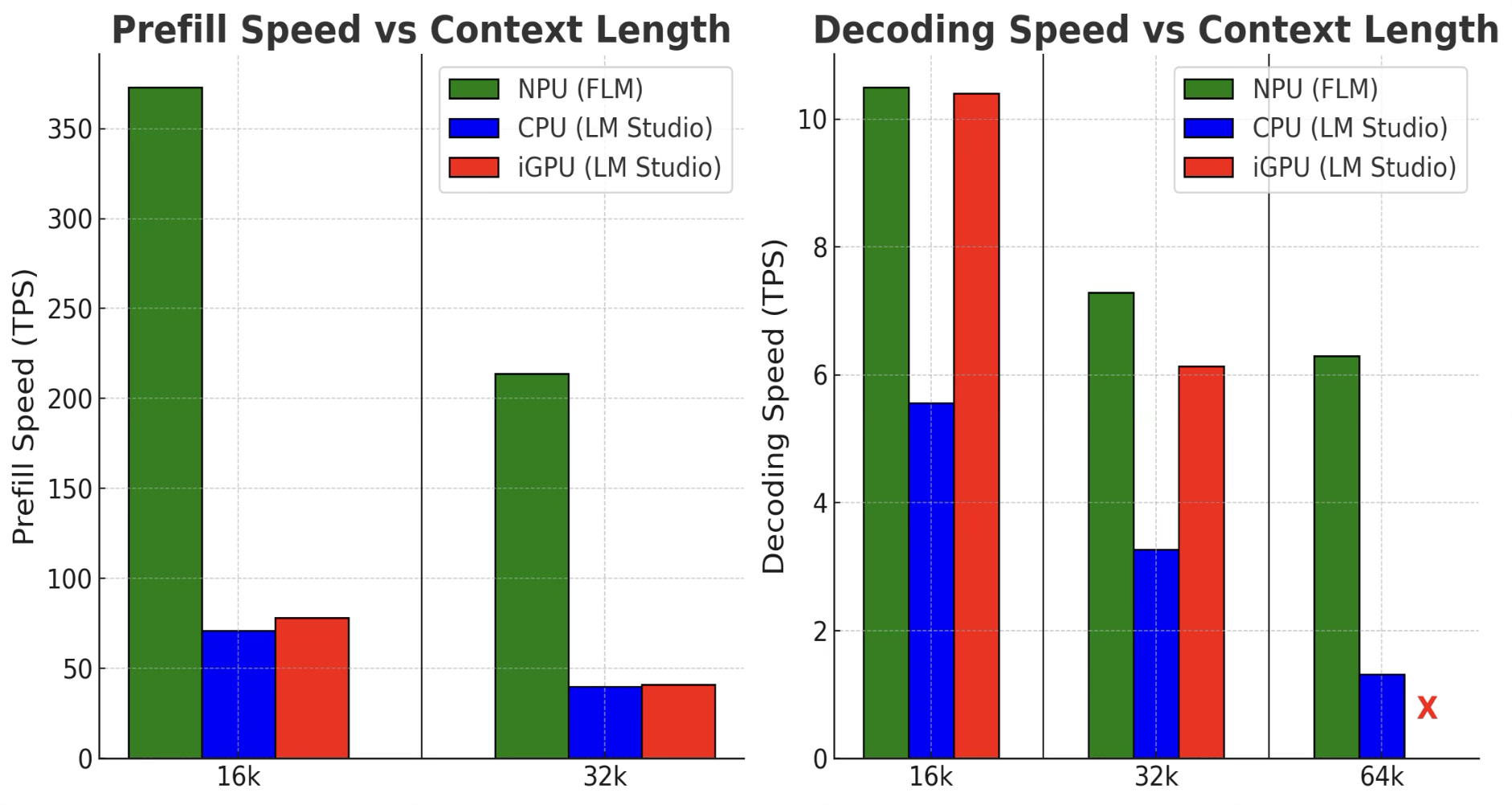
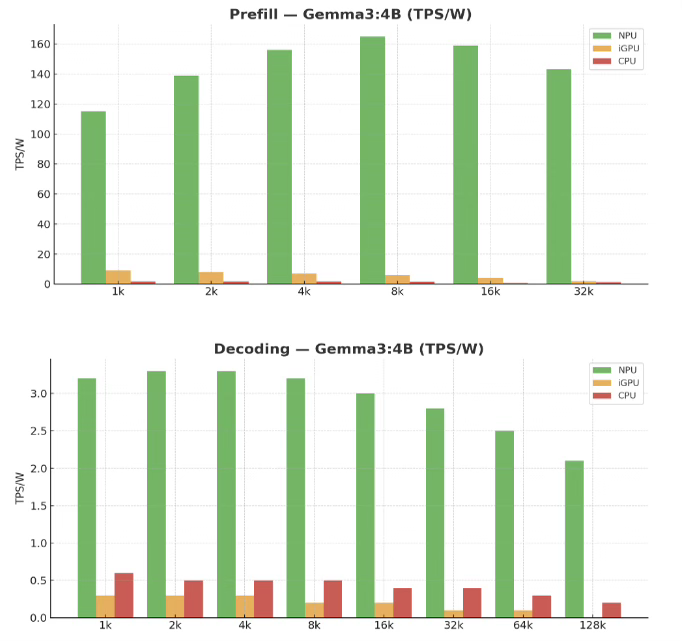
Gemma3 4B Vision
Image + text throughput on-device
Qualcomm reference telemetry