Demos
See FastFlowLM running on real hardware
Explore live demos and recordings that showcase FastFlowLM powering LLMs, VLMs, and embeddings fully on the Ryzen™ AI NPU. From interactive chat experiences to system integrations, these examples highlight what’s possible when you make the NPU the primary inference engine.
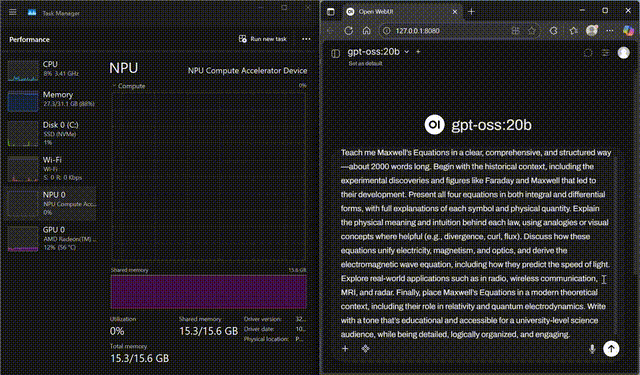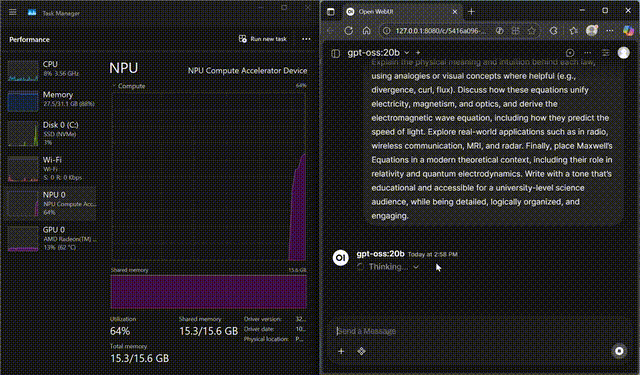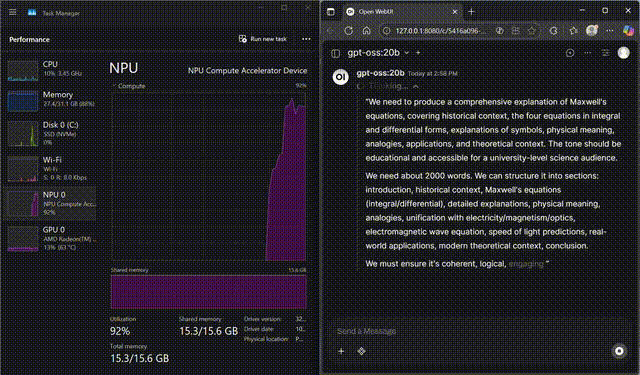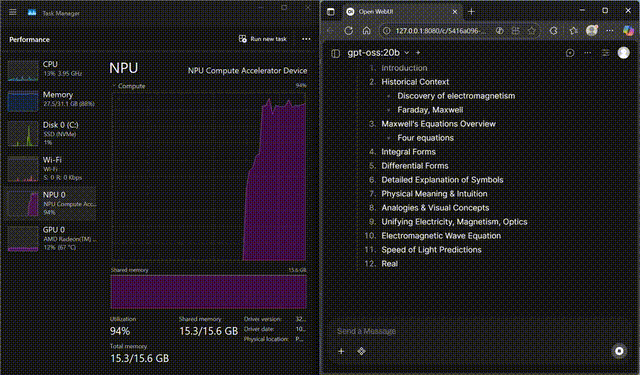
GPT-OSS on NPU
GPT-OSS-20B streaming fully on the Ryzen™ AI NPU
Stream GPT-OSS-20B locally with FastFlowLM, keeping CPU and GPU usage minimal while the NPU does the heavy lifting.
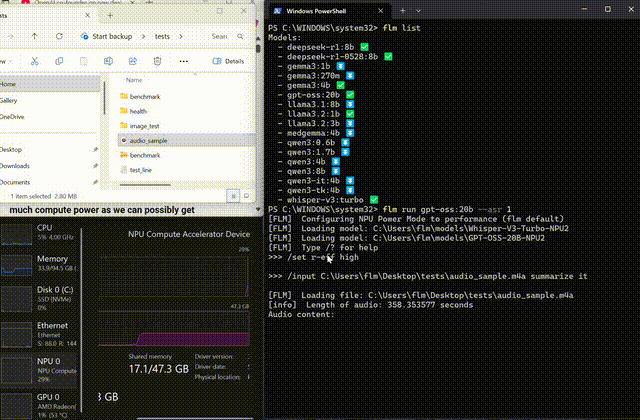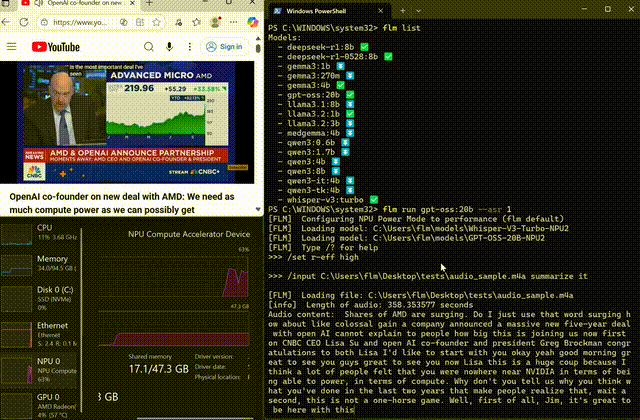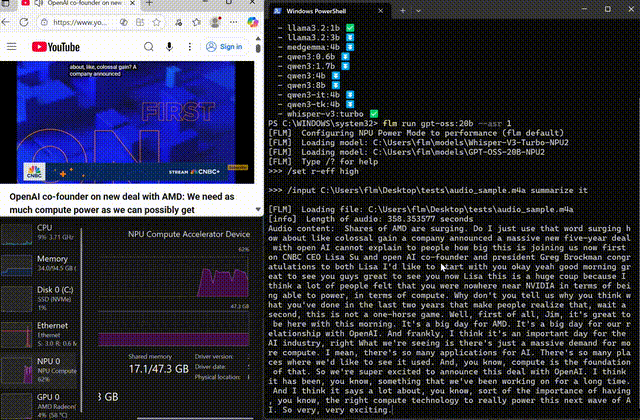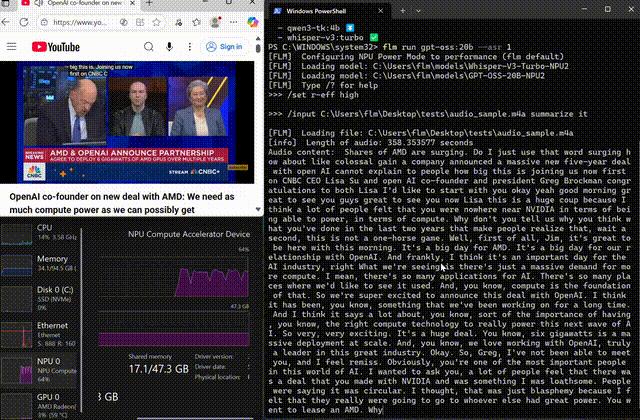
Whisper on-device
Transcribe and summarize long-form audio locally
Use FastFlowLM to run Whisper completely on the NPU, keeping voice and meeting data on your device while you transcribe and summarize hours of audio.
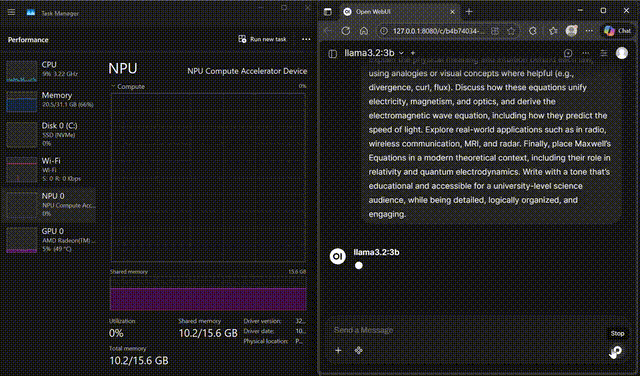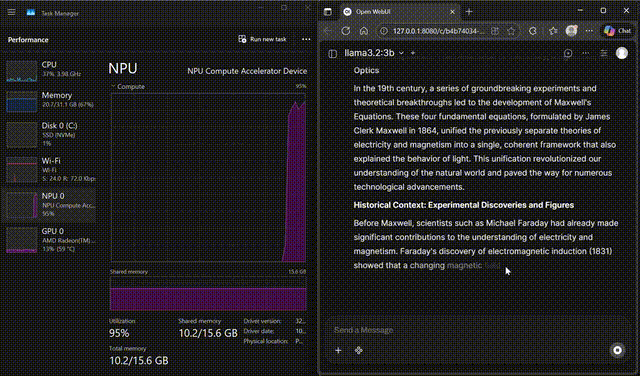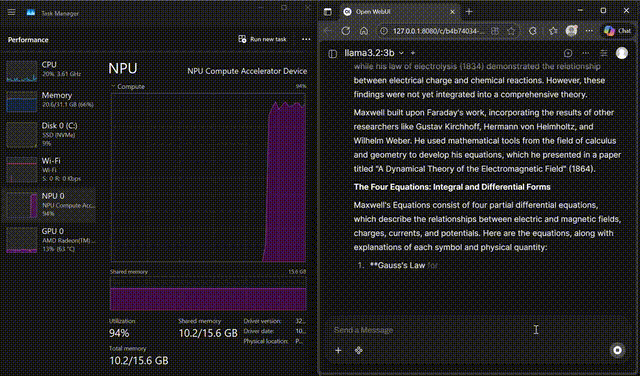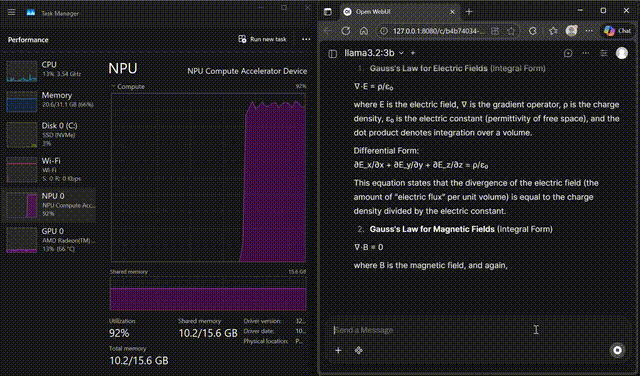
Llama 3.2 on WebUI
Interact with Llama 3.2-3B through the FastFlowLM WebUI
Chat with Llama 3.2-3B in a browser-based UI powered by FastFlowLM, with responses served directly from the Ryzen™ AI NPU.