NPU-first runtime
The fastest, most efficient LLM inference on NPUs
FastFlowLM delivers an Ollama-style developer experience optimized for tile-structured NPU accelerators. Install in seconds, stream tokens instantly, and run context windows up to 256k — all with dramatically better efficiency than GPU-first stacks. Our GA release for AMD Ryzen™ AI NPUs is available today, with betas for Qualcomm Snapdragon and Intel Core Ultra coming soon.
-
Runtime size
~16 MB
-
Context
Up to 256k tokens
-
Supported chips
Ryzen™ AI (Strix, Halo, Kraken)
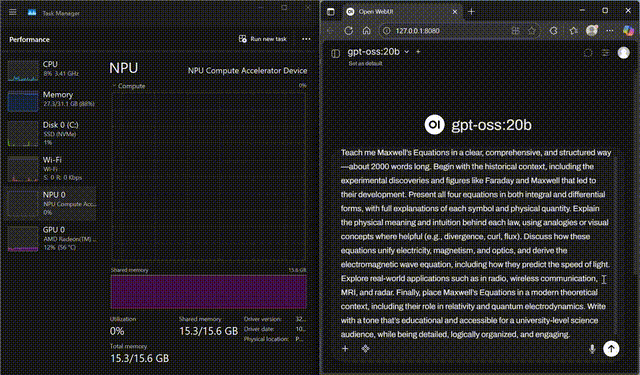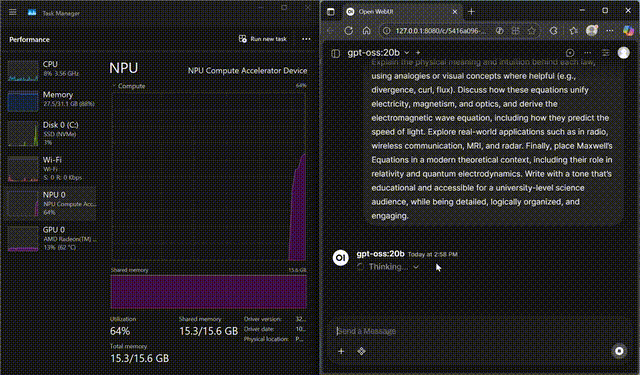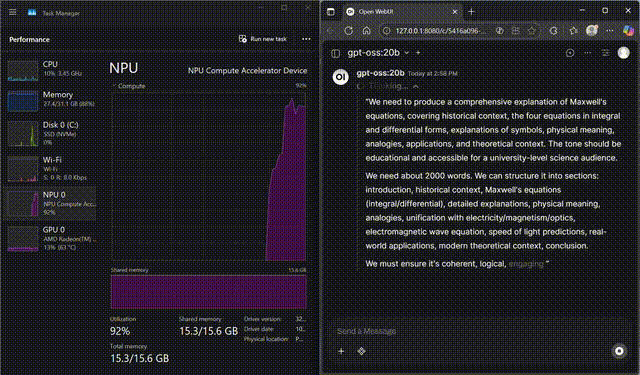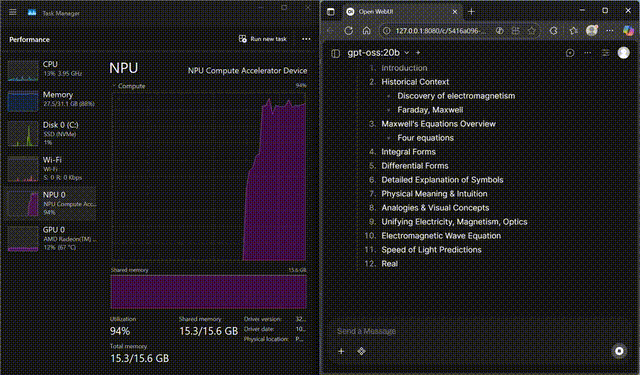
GPT-OSS on NPU
GPT-OSS-20B streaming fully on the Ryzen™ AI NPU
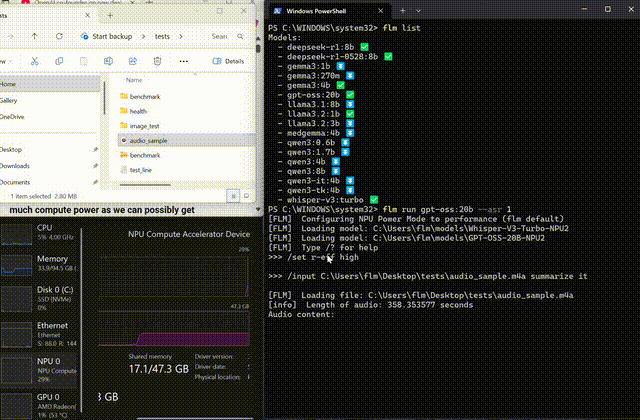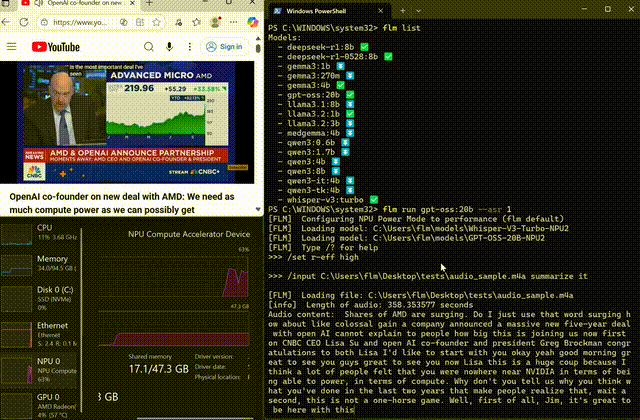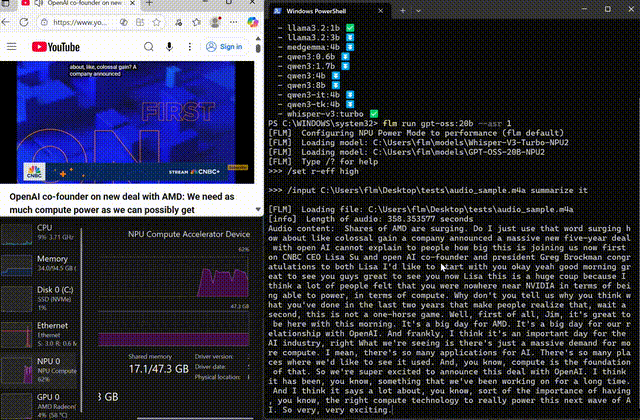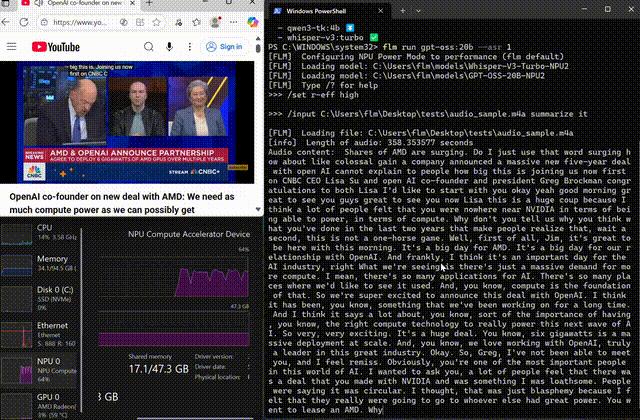
Whisper on-device
Transcribe and summarize long-form audio locally
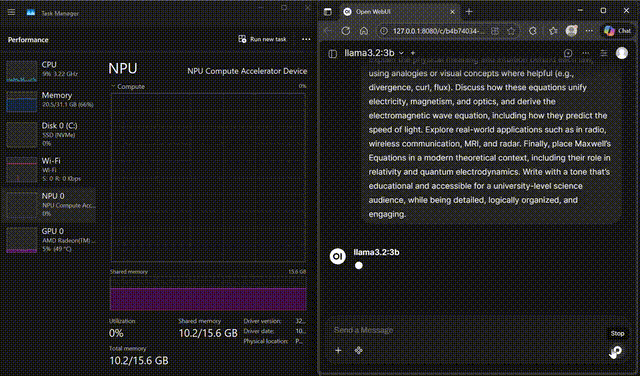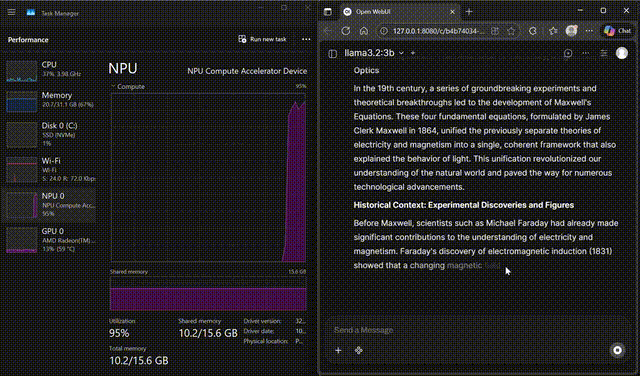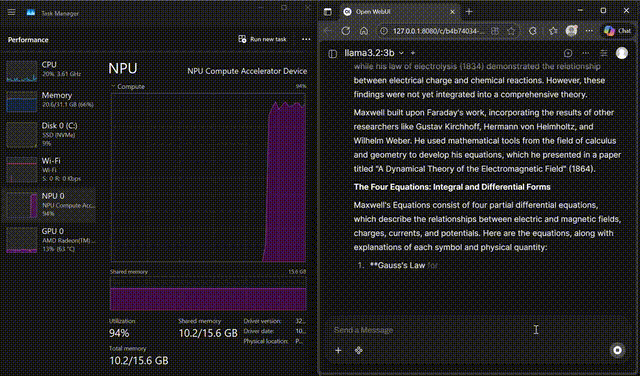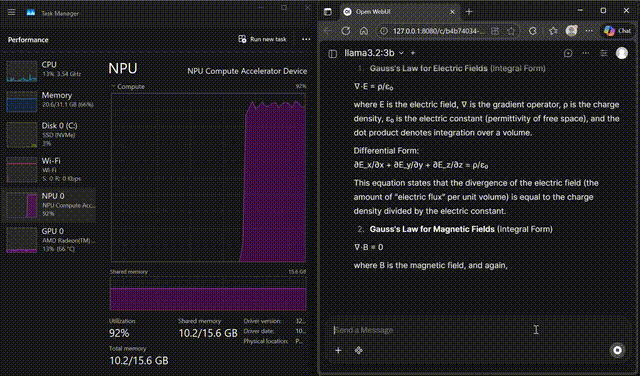
Llama 3.2 on WebUI
Interact with Llama 3.2-3B through the FastFlowLM WebUI
Install
From download to first token in under a minute
FastFlowLM ships as a 16 MB runtime with an Ollama-compatible CLI. No CUDA, no drivers, no guesswork—just run the installer, pull a model, and start chatting.
-
Zero-conf installer
Signed FastFlowLM installers cover every Ryzen™ AI laptop—just download and run.
-
Drop-in APIs
Compatible with Ollama, OpenAI, and Open WebUI endpoints for existing tooling.
-
Secure by default
Local auth tokens, TLS, and offline mode keep your data on-device.
Quickstart
CLI
Invoke-WebRequest https://github.com/FastFlowLM/FastFlowLM/releases/latest/download/flm-setup.exe `
-OutFile flm-setup.exe
Start-Process .\flm-setup.exe -Wait
flm pull llama3.2:3b
flm run llama3.2:3b --ctx 256k
APIs
POST /v1/chat/completions
Authorization: Bearer $FLM_TOKEN
curl -s localhost:11434/api/generate \
-d '{"model":"gemma3:4b","prompt":"hello"}'Models
One CLI, every Ryzen-ready model
Pull curated FastFlowLM recipes. The runtime streams tokens via HTTP, WebSocket, or the Ollama-compatible API, so existing apps work without rewrites.
Flagship reasoning
Llama 3.2 · DeepSeek · Qwen 3
Optimized kernels for 70B down to 1B, with automatic quantization and smart context reuse.
Vision & speech
Gemma 3 VLM · Whisper · Gemma Audio
VLM and audio pipelines run on the NPU, enabling private multimodal assistants.
Edge fine-tuning
FLM MoE + Embedding suites
Use built-in adapters, LoRA checkpoints, and embedding endpoints for retrieval workflows.
Benchmarks
Proof on silicon, not slides
FastFlowLM is tuned on real Ryzen™ AI hardware with synthetic and application-level workloads. Expect steady 40–80 tok/s on 7B models at < 10 W, plus deterministic latency for agentic chains.
-
Full-stack telemetry
Counters for NPU, CPU, and memory let you see exactly where cycles go.
-
Scenario-driven suites
Instruction tuning, RAG, chat, and multimodal tests mirror real workloads.
Llama3.2 3B @ 4-bit
72 tok/s
Ryzen™ AI 9 HX 370 · 8 ms median latency
Gemma 3 4B Vision
18 fps
Vision + text pipeline on XDNA2 with shared memory
Power draw
9.6 W
Full assistant stack vs ~45 W GPU baseline
Remote test drive
No Ryzen™ AI hardware yet? Launch the hosted FastFlowLM + Open WebUI sandbox and stream from a live AMD Ryzen™ AI box with 96 GB RAM.
-
Live hardware
Same builds we use internally, refreshed with every release.
-
Guest access
Instant login with rotating demo credentials.
-
Bring your apps
Point your HTTP client at the public endpoint to try agent flows.